Of these 93 are in the WALS 100-language sample, 90 are in the 200-language sample but not in the 100-language one, and 17 are in neither, but happen to be well-documented.
The languages again, in increasing order of weirdness (the equals sign means a tie between the two blandest languages, because mirabile dictu they share all values despite having nothing in common):
Koyraboro Senni = Yaqui, Ndyuka, Una, Bambara, Khasi, Meithei, Bribri, Thai, West Makian, Chinantec (Lealao), Suena, Bawm, Daga, Mundari, Purépecha, Evenki, Alamblak, Kilivila, Khalkha, Usan, Tagalog, Comanche, Imonda, Hindi, Fur, Kobon, Russian, Shipibo-Konibo, Kannada, Garo, Araona, Kunama, Koromfe, Taba, Diola-Fogny, Kayah Li (Eastern), Maung, Korean, Cahuilla, Tonkawa, Kanuri, Achumawi, Paamese, Indonesian, Maori, Tukang Besi, Dani (Lower Grand Valley), Marind, Tiwi, Mixtec (Chalcatongo), Yidiny, Malagasy, Sanuma, Beja, Ika, Sentani, Asmat, Nkore-Kiga, Supyire, Otomí (Mezquital), Qawasqar, Martuthunira, Maba, Wappo, English, Miwok (Southern Sierra), Gooniyandi, Basque, Fijian, Zuni, Rapanui, Greek (Modern), Bagirmi, Mangarrayi, Dumo, Tunica, Apurinã, Burmese, Hmong Njua, Maybrat, Pomo (Southeastern), Campa (Axininca), Batak (Karo), Ungarinjin, Ainu, Chamorro, Nahuatl (Tetelcingo), Amharic, Abipón, Swahili, Arapesh (Mountain), Kayardild, Latvian, Maranungku, Drehu, Kiribati, Yoruba, Georgian, Kewa, Persian, Greenlandic (West), Vietnamese, Mapudungun, Luvale, Krongo, Khmer, Murle, Nivkh, Turkish, Wambaya, Grebo, Ewe, Koasati, Yurok, Finnish, Amele, Maidu (Northeast), Wardaman, Urubú-Kaapor, Hungarian, Karok, Yagua, Warao, Paiwan, Guaraní, Hixkaryana, Spanish, Lango, Hamtai, Ket, Slave, Maricopa, Burushaski, Kera, Haida, Yimas, Aymara, Carib, Epena Pedee, Cree (Plains), Lakhota, Passamaquoddy-Maliseet, Sango, Japanese, Canela-Krahô, Dagur, Yuchi, Navajo, Jakaltek, Wintu, Pirahã, Kawaiisu, Rama, Nez Perce, Cayuvava, Coos (Hanis), Hausa, Chukchi, Ngiti, Hunzib, Ju|'hoan, Lavukaleve, Trumai, Mandarin, Oromo (Harar), Arabic (Egyptian), Tsimshian (Coast), Cubeo, Nunggubuyu, Pitjantjatjara, Khoekhoe, Quileute, Kutenai, Lezgian, Oneida, Ladakhi, Wichí, French, Squamish, Lepcha, Zoque (Copainalá), Yukaghir (Kolyma), Wichita, Nasioi, Semelai, Ekari, Zulu, Paumarí, //Ani, Awa Pit, Wari', Tlingit, Armenian (Eastern), Kiowa, German, Nenets, Khmu', Abkhaz, Iraqw
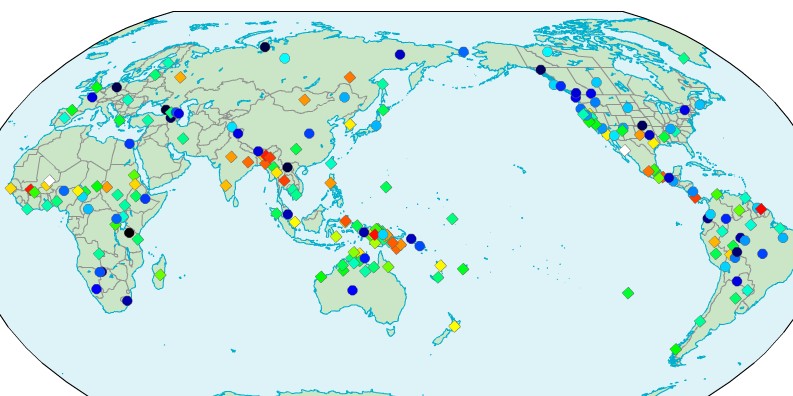 On the map the 130 blandest languages are marked by diamonds and the 70 weirdest ones by circles, with the colours progressing from white (the two blandest ones) to red-orange-yellow-green-cyan-blue-black (the weirdest one).
One may note that almost all languages in India are in the blandest one-sixth, as are half of the languages of Papua New Guinea; that in Africa the blandest languages are all on almost the same latitude, but on different longitudes from far west to far east; and that in the Americas most languages are relatively weird, the bland ones being few and scattered wide, but not very far north or south.
On the map the 130 blandest languages are marked by diamonds and the 70 weirdest ones by circles, with the colours progressing from white (the two blandest ones) to red-orange-yellow-green-cyan-blue-black (the weirdest one).
One may note that almost all languages in India are in the blandest one-sixth, as are half of the languages of Papua New Guinea; that in Africa the blandest languages are all on almost the same latitude, but on different longitudes from far west to far east; and that in the Americas most languages are relatively weird, the bland ones being few and scattered wide, but not very far north or south.
Overall there is a −0.308492644 correlation between a language's blandness and its distance from the 13½th parallel north. Of the languages up to 26 degrees north and south of this parallel, 68 are at least as bland as Batak (Karo) and 62 are at least as weird as Ungarinjin; beyond these latitudes the corresponding numbers are 16 (bland) and 54 (weird).
If Volapük were included, it would end up in the 97th place, between Maranungku and Yoruba. It would still be in the blander half, but only just.
If Klingon were included, it would be last but one (200th of 201), between Abkhaz and Iraqw. Thus it is very weird indeed, but not much weirder than all Terran languages — not even weirder than all of them. It even shares the values of six features with English (a.k.a. Federation Standard), from which it tries to be as dissimilar as possible (1A an average-size consonant inventory, 4A voicing in both plosives and affricates, 7A no glottalised consonants, 11 no front rounded vowels, 11A all common types of consonants present, 48A no person marking on adpositions).
Koyra Chiini, Lahu, Adzera, Polish, Nandi, Berta, Kashmiri, Komo, Zande, Mumuye, Tigak, Albanian, Yapese, Atayal, Kurdish (Central), Malakmalak, Ijo (Kolokuma), Doyayo.In the rank ordering Koyra Chiini fits in the third place, between its sister Koyraboro Senni (as well as Yaqui) and Ndyuka. (The only difference is that Koyra Chiini is VO rather than OV.) Lahu is between Dani (Lower Grand Valley) and Marind; Adzera, between Qawasqar and Martuthunira. The place of Polish is between Fijian and Zuni. (It is significantly more weird than Russian because it has a large consonant set, as opposed to a moderate one, and especially because it's undecided between SV and VS.) Of the other Indo-European languages, Kashmiri is between Maranungku and Drehu (in the bland half, but close to the border); Albanian, between Tsimshian (Coast) and Cubeo; Kurdish (Central), between Kutenai and Lezgian. Ijo (Kolokuma) fits between Semelai and Ekari. But the weirdest one is Doyayo, which ranks in the last place but one, between Abkhaz and Iraqw.
The weirdest thing about Esperanto is that its personal pronouns distinguish gender, albeit in the 3rd person singular only (44A). This value is shared by 30 languages.
The weirdest thing about Hindi is its large consonant inventory (1A), 34 segments or more (UPSID lists 38).
The weirdest thing about Russian is its high consonant-vowel ratio (3A), above 6.5 (UPSID finds 33 consonants and 5 vowels, yielding a ratio of 6.6).
The weirdest thing about Indonesian is that only the patient argument is marked in the verb (102A).
The weirdest thing about English are its interdental fricatives (19A).
The weirdest thing about Volapük are its front rounded vowels, both mid and high (11A).
The weirdest thing about Mandarin is its high front rounded vowel (also 11A).
The weirdest thing about German is that its negative particle can both precede and follow the verb (143A).
The weirdest thing about Abkhaz is that its negative affix can both precede and follow the root (143A).
The weirdest thing about Klingon is the tripartite alignment of its verbal person marking (100A), something unseen in my sample.
The weirdest thing about Doyayo is that it has optional triple and obligatory double negation (143A), which is also unseen in the sample.
The weirdest thing about Iraqw is that its personal pronouns distinguish gender, but not in the 3rd person (44A), also a feature that no other language in the sample has.
There are only two other languages that are unique in some respect: Nenets has both interdental fricatives and pharyngeals (19A), and Khmu' has both implosives and glottalised resonants (7A).
No two languages differ in all 20 values, but Nunggubuyu differs from Iraqw in 19, as do Wambaya and Oneida from //Ani, and Burmese and Hunzib from Wari'. Nine languages (Basque, Comanche, Daga, Hindi, Kanuri, Kunama, Mundari, Purépecha, Una) differ least (in 14 values) from the ones from which they differ most.
Indonesian differs least (in 4 values) from Chinantec (Lealao), Dagur, Hindi, Khasi and Russian, and most (in 15) from Tlingit.
English differs least (in 4 values) from French, Russian and Volapük, and most (in 17) from Tlingit.
Esperanto differs least (in 3 values) from Mandarin, and most (in 16) from Tlingit.
Volapük differs least (in 4 values) from Dagur, English, Finnish and French, and most (in 17) from Tlingit again.
Tlingit differs least (in 8 values) from Aymara, Cahuilla, Navajo and Wichita, and most (in 18) from Cubeo, Drehu, French, German and Latvian.
Abkhaz differs least (in 9 values) from Burushaski and Tlingit, and most (in 18) from Maori.
Klingon differs least (in 8 values) from Kunama, and most (in 16) from Finnish, Kayardild and Martuthunira.
To be sure, a simple count of shared feature values, with no weights assigned to them, is a very rough measure of the similarity between languages. If we use it to divide all 200 sample languages into two classes, so as to maximise the number of token differences between languages of different classes and to minimise the number of differences within each class, the languages will split almost by features 102A and 104A (that is, by whether the verb expresses both the A and P arguments or not). (The three exceptions are Kanuri, Kunama and Maba, all of which do express both A and P in the verb but otherwise share slightly more values with languages of the other class.) This is an effect of the correlation between features 102A and 104A (as well as 100A and 103A).
If we use these weights when dividing all 200 sample languages into two classes as said above, the split turns out to be mainly by feature 83A Order of Object and Verb: all languages with VO or no dominant order are in one class (97 members), all OV languages are in the other (103 members). There are three exceptions: Wichita (OV) is in the first class and Karok and Trumai (no dominant order) are in the second. Unsurprisingly, this division correlates with 82A Order of Subject and Verb, because all languages in the second class are SV, except for Hixkaryana and Cubeo. And also, less strongly, with 143A Order of Negative Morpheme and Verb: the first class contains more, and the second less, of their fair shares of negative preverbal particles, and with negative suffixes it's the other way around.
From blandest to weirdest, they go (non-sample languages in italics):
Indonesian, Una, Bawm, West Makian, Hindi = Koyraboro Senni = Yaqui, Khasi, Koyra Chiini, Basque, Ndyuka, Maung, Purépecha, Daga = Kunama, Meithei, Suena, Evenki = Mundari, Kanuri, Comanche, Bambara, Beja, Fur = Taba, Bribri, Thai = Tonkawa, Marind, Paamese = Russian, Miwok (Southern Sierra), Kobon, Chinantec (Lealao) = Usan, Imonda, Abipón, Kannada, Tiwi, Amele, Maba, Achumawi, Tukang Besi, Dagur, Alamblak, Esperanto, Khalkha = Ladakhi, Dani (Lower Grand Valley), Diola-Fogny = Rama, Kewa, Batak (Karo), Maidu (Northeast) = Sentani, Kilivila, Lavukaleve, Kayah Li (Eastern), Araona, Komo, Asmat, Cahuilla = Koromfe, Warao, Chamorro = Mangarrayi = Shipibo-Konibo = Tagalog, Dumo, Garo, Lahu, Gooniyandi, Luvale, Supyire, Wappo, Hmong Njua = Karok, Tigak, Zoque (Copainalá), Urubú-Kaapor, Bagirmi = Tunica, Polish, Nkore-Kiga, Fijian, Chukchi, Nenets = Yoruba, Ainu, Ika, Hungarian, Sanuma, Mixtec (Chalcatongo) = Yurok, Turkish, Adzera = Guaraní, Ewe = Maori, Yukaghir (Kolyma), Canela-Krahô, Nahuatl (Tetelcingo), Korean, English = Qawasqar, Nandi, Ekari, Swahili, Vietnamese, Otomí (Mezquital), Ungarinjin, Volapük, Greek (Modern) = Kashmiri, Yidiny, Mapudungun, Lango, Kera, Maybrat, Maranungku = Pitjantjatjara, Apurinã, Arapesh (Mountain) = Lepcha, Mandarin, Khmer, Georgian = Latvian, Rapanui, Khmu', Berta, Finnish = Persian, Awa Pit, Zuni, Martuthunira, Oromo (Harar), Spanish, Grebo = Malagasy, Semelai, Amharic, Nivkh, Mumuye, Carib, Epena Pedee, Burmese, Malakmalak, Campa (Axininca) = Nasioi, Wichí, Greenlandic (West) = Zande, Japanese, Ket = Wardaman, Kawaiisu, Lakhota, Albanian = Doyayo, Kiribati, Pirahã, Yimas, Koasati, Hixkaryana, Slave, Khoekhoe, Wambaya, Maricopa, Sango, Pomo (Southeastern), Murle, Passamaquoddy-Maliseet, Kayardild, Burushaski, Kiowa, Hausa, Yuchi, Ngiti, Drehu, Hamtai, Ijo (Kolokuma), Trumai, Ju|'hoan, Yagua, Paiwan, Krongo, Kurdish (Central), Armenian (Eastern), Cayuvava, Aymara, French, Oneida, Atayal, Yapese, Haida, Lezgian, Navajo, Arabic (Egyptian), Jakaltek, Zulu, Cree (Plains), German, Klingon, Hunzib, Cubeo, Nez Perce, Wichita, Kutenai, Iraqw, Coos (Hanis), Nunggubuyu, Tsimshian (Coast), Wintu, Wari', Paumarí, //Ani, Tlingit, Squamish, Quileute, Abkhaz.